Linux Networking Introduction
this article is intended for an audience which does not necessarily have a Computer Science or Information Technology background and are curious about how things work. The goal is that by the end of the article, as someone just arriving to the Linux universe, you will be able to have basic understanding of how the Linux Operating System (OS) works, how you can connect two or more Linux systems through a network, simple best practices to keep your system safe, and other (maybe useful) tips. Take everything with a pinch of salt as I will be simplifying some of the topics.
Requirements
To fully follow this course, you should have at least two computers available. If you do not have a spare old computer gaining dust in the attic you can use VirtualBox (take a look at this guide on how to set it up) or use a similar software with either NAT Networking or Bridged network configuration.
We assume those machines have either Ubuntu 20.04 (Focal Fossa) or Debian 10 (Buster) installed. The requirements for either of them with a Desktop environment are:
- 2 GHz single core processor
- 2 GiB RAM (system memory)
- 10 GB of hard drive space
of course the more the merrier. Remember that these requirements are the recommended minimum for a usable Linux OS.
The OS installation itself is outside of the scope of this article, however if you are to follow the defaults you should at least be able to follow this course =)
Introduction
During the SARS-CoV-2 pandemic I was reached out by people wanting to start using Linux as an alternative everyday-use Operating System, most of them were familiar with Ubuntu or some other Debian-based variation, or by people who now had to interact with Linux systems. Eventually some reached a point where they had to open a command-line to follow a set of instructions they did not really understand. Among those, there were some who were curious enough to ask "what does this do?" or "why does this do what it does?". Those that made those questions eventually caught themselves delving deeper into Linux internals and how everything fits together.
This made me think it would be worthwhile to write a small course-like article introducing new users into this complex universe that is Linux.
I have given this article the title Linux Networking Introduction because in today's perspective what would we really do with a Linux system without networking? But mostly because the people that have a need to interact with a Linux system usually do it by means of a network connection.
That said, in this course we will go through:
- A Bit of Linux History
- An Overview of Linux Kernel Components
- An Overview of the Linux Filesystem
- User Authentication and Security
- File Attributes and Ownership
- Bash, your friendly command-line interpreter
- Networking 101
- Secure Communications and SSH
- Setting up your machine for remote access
This is a fairly extensive article, so I invite you to take a break between sections, take some time to sink all in and try your own version of the examples.
Have a nice ride :-)
A Bit of Linux History
Before talking specifically about Linux we can go a bit further back to 1969 at AT&T Bell Labs, where Dennis Ritchie, Kenneth Thompson, and other colleagues began developing a small operating system for a very specific minicomputer. That operating system was named Unix as a result of cooperation between Bell Labs and the academic community, in 1979 the "seventh edition" (V7) version of Unix was released, the base for every still existing Unix system. [1]
In 1984, Richard Stallman's Free Software Foundation (FSF) began the GNU project, which had the objective of creating a freely used, read, modified and redistributed version of the Unix operating system. The FSF created useful (and still used today) components. However, the FSF had trouble with developing an operating system kernel to replace the Unix one (Hurd) and while they were developing it the Linux Kernel was released, filling the kernel gap in the GNU Project. [2]
In 1987, Andrew S. Tanenbaum developed MINIX, as a teaching tool for his textbook Operating Systems Design and Implementation published in the same year. This was used by many students taking introductory courses on computer operating systems, and one of them was Finnish student Linus Torvalds.
In 1991, Linus Torvalds started a new project, which would later be called Linux. After a couple of months working on it he reached out to the MINIX community for help, this marked what became the start of one of the biggest open-source software projects:
Hello everybody out there using minix -
I'm doing a (free) operating system (just a hobby, won't be big and
professional like gnu) for 386(486) AT clones. This has been brewing
since april, and is starting to get ready. I'd like any feedback on
things people like/dislike in minix, as my OS resembles it somewhat
(same physical layout of the file-system (due to practical reasons)
among other things).
I've currently ported bash(1.08) and gcc(1.40), and things seem to work.
This implies that I'll get something practical within a few months, and
I'd like to know what features most people would want. Any suggestions
are welcome, but I won't promise I'll implement them :-)
Linus (torv...@kruuna.helsinki.fi)
PS. Yes - it's free of any minix code, and it has a multi-threaded fs.
It is NOT protable (uses 386 task switching etc), and it probably never
will support anything other than AT-harddisks, as that's all I have :-(.You can check the full conversation (plus more recent comments) in Google groups
8 years later, Linus Torvalds stated that Linux at the time had millions of users, thousands of developers, and a growing market. It is used in embedded systems; it is used to control robotic devices; it has flown on the space shuttle. I'd like to say that I knew this would happen, that it's all part of the plan for world domination. But honestly this has all taken me a bit by surprise I was much more aware of the transition from one Linux user to one hundred Linux users than the transition from one hundred to one million users. [3]

Tux - the Linux mascot
23 years later, Linux is now the world’s largest and most pervasive open source software project in the history of computing. The Linux Kernel is the largest component of the Linux operating system and is charged with managing the hardware, running user programs, and maintaining the security and integrity of the whole system [5] as we will see throughout this course.
An Overview of Linux Kernel Components
In Figure 2 we can see how different hardware parts connect to make your computer's architecture. As a bare minimum you should have a Central Processing Unit (CPU), some amount of Random Access Memory (RAM), some amount of storage in the form of a Hard Disk Drive (HDD) or Solid State Drive (SSD), and some peripherals (i.e: your monitor, keyboard and mouse). You can have more peripherals, different kinds of storage, or even more hardware connected to the Input/Output (I/O) Bus (like network cards and graphics cards), but you cannot have less in order for an operating system to function properly.
{kind=link}
The operating system is what makes every one of these components work together, and some at all.
In Figure 3 we can see an overview of the different layers of abstraction that make the Linux Kernel architecture.
The bottom layer (the first), we have already mentioned earlier, represents every component physically connected to your computer.
{kind=link}
The middle layer represents the Kernel Space, this is a very special layer as it can interact directly with all the hardware connected to your computer, it has the most privileges and can:
- manage which process is running on the CPU, through Process Management
- manage memory allocation for individual processes, and even memory shared between processes, through Memory Management
- read and write storage devices through File Systems
- draw images on your screen, send data through a network card, control a wide LED panel, or any other connected device through Device Drivers
- interact with other devices connected to a network through Networking
The top layer, and the one you usually interact with, is User Space. Here is where we have System Applications that can perform special administrative tasks, User Applications like a browser or a music player, and Tools, which may go somewhere in between the previous two, available to all and may support applications, like software libraries.
In sum, in the Hardware layer is every device connected to you computer and every thing that makes your computer a computer. In the Kernel Space layer is every Kernel component that interacts directly with Hardware. In the User Space layer we have applications and tools that allow us to reach the Hardware, always going through the Kernel Space layer.
An Overview of the Linux Filesystem
When migrating from another operating system such as Microsoft Windows to another; one thing that will profoundly affect the end user greatly will be the differences between the filesystems. [7]
A filesystem is the methods and data structures that an operating system uses to keep track of files on a disk or partition; that is, the way the files are organized on the disk. The word is also used to refer to a partition or disk that is used to store the files or the type of the filesystem. Thus, one might say I have two filesystems meaning one has two partitions on which one stores files, or that one is using the extended filesystem, meaning the type of the filesystem. [7]
The difference between a disk or partition and the filesystem it contains is important. A few programs (including, reasonably enough, programs that create filesystems) operate directly on the raw sectors of a disk or partition; if there is an existing file system there it will be destroyed or seriously corrupted. Most programs operate on a filesystem, and therefore won't work on a partition that doesn't contain one [7]
So we can look at the Linux Filesystem as a set of folders, or directories, that each have some associated function. They can contain configuration files necessary for a proper operation of the Linux operating system, they can contain applications (executable files), or they can contain arbitrary files such as our family photos or personal documents.
The most top-level directory, which contains every other directory, is called the root directory and is represented by a forward slash (/).
The following directories usually exist in / :
| Directory | Description |
|---|---|
| /bin | Essential command binaries |
| /boot | Static files of the boot loader |
| /dev | Device files |
| /etc | Host-specific system configuration |
| /home | User home directories |
| /lib | Essential shared libraries and kernel modules |
| /media | Mount point for removable media |
| /mnt | Mount point for mounting a filesystem temporarily |
| /opt | Add-on application software packages |
| /proc | Process information pseudo-file system |
| /root | Home directory for the root user |
| /run | Operating system runtime information |
| /sbin | Essential system binaries |
| /srv | Data for services provided by this system |
| /tmp | Temporary files |
| /usr | Secondary hierarchy |
| /var | Variable data |
For operating systems using the systemd init system some of these directories still exist for compatibility, however in another form. They "point" to their homonyms under /usr secondary hierarchy directory, these are:
- /bin, /sbin/ which all point to /usr/bin
- /lib which points to /usr/lib
For more information you can see systemd documentation regarding file system hierarchy.
User Authentication and Security
In order for the kernel to be able to identify who is trying to access, modify or execute anything in the system it has to have some type of authentication system. We will have two important categories, users and groups.
User information is usually stored in your filesystem in the file /etc/passwd. In this file each line represents a user and its information separated by a colon (:).
account:password:UID:GID:GECOS:directory:shell| Field | Description |
|---|---|
| account | The user's name. Should not contain uppercase letters |
| password | Encrypted user password or asterisks |
| UID | Numerical identification of the user |
| GID | Numerical identification of the user's primary group |
| GECOS | Optional field used for information purposes only. It usually contains the user's full name |
| directory | The user's home directory |
| shell | The command line interpreter to be used after login. |
an example of a real user could be:
t0rrant:K3xcO1Qnx8LFN:1001:1001:Manuel Torrinha,,,:/home/t0rrant:/bin/bashGroup information is usually stored in your filesystem in the file /etc/group. In this file each line represents a group and, like the /etc/passwd file, its information separated by a colon (:).
group_name:password:GID:user_listEach field description can be seen in the table below:
| Field | Description |
|---|---|
| group_name | The name of the group |
| password | Encrypted group password. If empty, no password is needed |
| GID | The numeric group identification |
| user_list | a list of usernames that are members of this group, separated by commas (,) |
an example of a real group could be:
ourgroup::132:t0rrantWith this information the kernel can establish who as access to what, as we will see how it works for files in the next section, File Attributes and Ownership.
Shadow Passwords
You may have noticed that instead of an encrypted password in your /etc/passwd file you have something like:
t0rrant:x:1001:1001:Manuel Torrinha,,,:/home/t0rrant:/bin/bashThe /etc/passwd file, which contains information about all users, including their encrypted password, is readable by all users, making it possible for any user to get the encrypted password of everyone on the system. Though the passwords are encrypted, password−cracking programs are widely available. To combat this growing security threat, shadow passwords were developed [8]
When shadow passwords are enabled the password field in the /etc/passwd file is replaced by an "x" and the user's actual password (encrypted) is stored in the /etc/shadow file. This file is only readable by the root user which makes it a safer place to keep such sensitive information.
File Attributes and Ownership
On a Linux system, every file is owned by a user and a group user. There is also a third category of users, those that are not the user owner and don't belong to the group owning the file. [11]
For each of these user categories, we can enable or disable read, write, or execute permissions.
The owner and group user for a file is represented by its identifier (id), but more commonly you will see the name corresponding to that id for readability.
The permissions for each user category can be defined in octal (8 digit system instead of 10), which conveniently maps to a three digit binary, meaning that we can easily represent every combination of rwx (read, write, execute) with a single octal digit, as we can see in the table below:
| Octal | Binary | File Permission |
|---|---|---|
| 0 | 000 | --- |
| 1 | 001 | --x |
| 2 | 010 | -w- |
| 3 | 011 | -wx |
| 4 | 100 | r-- |
| 5 | 101 | r-x |
| 6 | 110 | rw- |
| 7 | 111 | rwx |
Directories are also files in their essence, but they are distinguished by a special bit which is either on or off, and represented by d or -, respectively.
So if we have a representation like this
drwxr-xr-x t0rrant t0rrant Personal
-rw-r----- t0rrant ourgoup private_fileit means that the directory Personal can be read and executed by its owner t0rrant, everyone in the group t0rrant and everyone else, but can only be written by its owner t0rrant. In octal we would represent this as 755.
The file private_file can be read by its owner t0rrant and everyone in the group ourgoup but can only be written by its owner t0rrant. In octal we would represent this as 640.
Every directory that should have the read permission has to also have the executable permission, or else it will not be accessible.
Besides using the octal notation we can also use a character notation, which is sometimes easier to add or remove permissions from a file. This notation is used by defining one or more of user (u), group (g) or other (o) categories, followed by the plus (+) sign if we want to add, or minus (-) if we want to remove permissions, followed by the permissions we want to add or remove in rwx form.
So if we, for example, wanted to add just writable permissions to the file private_file for members of the group ourgroup we could do so by writting g+w. Seemingly, if we wanted to add executable permissions to the same file to the owner and group we would write ug+x.
File Types
In Windows systems you are probably used to distinguishing a file's type by its extension. If you have a file named myfile.pdf it represents a Portable Document Format (PDF) file, and Windows "knows" which application should open such a file because it has stored somewhere the relationship between file names ending in .pdf and the Adobe Reader application.
The same is not true for Linux systems. In fact, besides the file extension, the file itself has information of what type it is in the first bytes of the file. If we could take a look at the start of the PDF file as it were a normal text file we would see something like this:
%PDF-1.4Let us take a look at another file type, Portable Network Graphics (PNG) for example
�PNGThat � character appears because the content cannot be converted to another readable character, which means that there is something there, just not in a usual readable format.
So we can see that files themselves have information of which type of file they are.
Bash, your friendly command-line interpreter
Bash is the shell, or command language interpreter, for the GNU operating system. The name is an acronym for the Bourne-Again SHell, a pun on Stephen Bourne, the author of the direct ancestor of the current Unix shell sh, which appeared in the Seventh Edition Bell Labs Research version of Unix. [6]
In Linux graphical environments, the case with our Ubuntu 20.04, we can use Bash by launching the Terminal application which is usually associated with the icon seen in Figure 4 or some variation of it.
Gnome Terminal icon
When interacting with such Terminal applications we are presented a prompt followed by a flashing cursor, which represents where the next character we input will appear. The prompt usually has the following appearance:
<current user name>@<machine name>:<current working directory>$Most of you that have already interacted with a Linux system have probably copy & pasted some instructions to install an application or configure something in your system.
Now you will be able to better understand how those instructions work underneath.
Simple Commands
Here we will see some commands we can enter in Bash that interact with different Linux components.
User System
Identify the user running a command:
t0rrant@testing:~$ whoami
t0rrant
t0rrant@testing:~$See to which groups a user belongs:
t0rrant@testing:~$ groups
t0rrant sudo
t0rrant@testing:~$or a more broad user view:
t0rrant@testing:~$ id
uid=1001(t0rrant) gid=1001(t0rrant) groups=1001(t0rrant),27(sudo)
t0rrant@testing:~$ id root
uid=0(root) gid=0(root) grupos=0(root)
t0rrant@testing:~$File System
List files and directories located in our current working directory:
t0rrant@testing:~$ ls
Desktop Documents Downloads Images Music Videos
t0rrant@testing:~$or perhaps you have folders with other names, more folders, less folders...
It is also common to have coloured output, in which each colour represents a particular characteristic of the file. It may be that the file is a normal file (white), a directory (blue), an executable file (green), a link to another existing file (teal), a link to a non-existing file (red), a file that is accessible by any user (blue with a green highlight).
List files and directories for a specific location:
t0rrant@testing:~$ ls Images/
dontpanic.jpg
t0rrant@testing:~$List files, including hidden files:
t0rrant@testing:~$ ls -a
. .bashrc Downloads .profile
.. Desktop Images Videos
.bash_history Documents Music
t0rrant@testing:~$List files, and see more detailed properties:
t0rrant@testing:~$ ls -l
total 24
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Desktop
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Documents
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Downloads
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Images
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Music
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Videos
t0rrant@testing:~$Create an empty file or change its modification time, if it exists:
t0rrant@testing:~$ touch myfile
t0rrant@testing:~$ ls -l
total 24
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Desktop
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Documents
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Downloads
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Images
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Music
drwxr-xr-x 2 t0rrant t0rrant 4096 May 13 23:58 Videos
-rw-rw-r-- 1 t0rrant t0rrant 0 May 14 00:05 temp
t0rrant@testing:~$The echo command outputs whatever we pass to it:
t0rrant@testing:~$ echo Hello World
Hello WorldThis can be useful to, for example, add content to a file:
t0rrant@testing:~$ echo Hello World > temp
t0rrant@testing:~$The cat command outputs a file contents:
t0rrant@testing:~$ cat temp
Hello World
t0rrant@testing:~$The > character we used earlier redirects whatever would go to the output (standard output, or stdout) to a file, the file name is whatever comes after the >. This special character will overwrite the file contents entirely! So we can also use another special character, the >> which appends the content to the end of the file, i.e:
t0rrant@testing:~$ cat temp
Hello World
t0rrant@testing:~$ echo Hello World! > temp
t0rrant@testing:~$ cat temp
Hello World!
t0rrant@testing:~$ echo Goodbye World! >> temp
t0rrant@testing:~$ cat temp
Hello World
Goodbye World
t0rrant@testing:~$We can also see a list of previously run commands:
t0rrant@testing:~$ history
1 whoami
2 groups
3 id
4 ls
5 ls -a
6 ls -l
7 touch myfile
8 ls -l
9 echo Hello World
10 echo Hello World > temp
11 cat temp
12 cat temp
13 echo Hello World! > temp
14 cat temp
15 echo Goodbye World! >> temp
16 cat temp
17 historyAnd run one of those commands again with the ! special command:
t0rrant@testing:~$ !1
whoami
t0rrant
t0rrant@testing:~$We can also run the previous command by using the !! special command:
t0rrant@testing:~$ !1
whoami
t0rrant
t0rrant@testing:~$ !!
whoami
t0rrant
t0rrant@testing:~$Man Pages
A very (very!) helpful command is man. This command allows you to read the documentation for a specific item, also known as man pages. It makes use of the less command to read those files. You can use the arrow keys to move around, use the h key to see the help screen or the q key to exit.
t0rrant@testing:~$ man ls
LS(1) User Commands LS(1)
NAME
ls - list directory contents
SYNOPSIS
ls [OPTION]... [FILE]...
DESCRIPTION
List information about the FILEs (the current directory by default).
Sort entries alphabetically if none of -cftuvSUX nor --sort is speci‐
fied.
Mandatory arguments to long options are mandatory for short options
too.
-a, --all
do not ignore entries starting with .
-A, --almost-all
do not list implied . and ..
--author
Manual page ls(1) line 1 (press h for help or q to quit)
t0rrant@testing:~$There are even man pages for the man command, try it out!
Variables
A variable is a "word" you can assign a value to. Shell variables are defined in uppercase, by convention. Bash has two types of variables:
- Global (or environment) variables
- Local variables
Global variables are available in all Bash sessions, they can be displayed using the env command. These variables contain information that should be persistent across all shells, such as:
- the user running the shell, USER
- the name of the machine the shell runs in, HOSTNAME
- the path for the current working directory, PWD
- the path for the previous working directory, OLDPWD
- the language used by the system, LANGUAGE
- the path for the shell executable we are running, SHELL
Local variables are words specific to an execution environment. What this means is that if you define a variable in one Bash session, it is not available to another Bash session. They are also displayed with the env command, mixed with the environment variables.
Apart from dividing variables in local and global variables, we can also divide them in categories according to the sort of content the variable contains. In this respect, variables come in 4 types: [9]
- String variables
- Integer variables
- Constant variables
- Array variables
In order to simplify this subject we will focus on String and Integer variables only.
To assign a value to a variable, in a shell, we do the following:
t0rrant@testing:~$ MYVAR="myvalue"
t0rrant@testing:~$We should not put spaces around the equal (=) sign, as it will cause the shell to error. It is also a good practice to always surround our String variables with quotes in order to reduce our chances of making errors.
To access a variable's value we use the dollar ($) sign in the form $VARNAME
t0rrant@testing:~$ echo $MYVAR
myvalue
t0rrant@testing:~$In the case of local variables defining a variable in the form VARNAME=value make the variable only available to the current shell, but not to applications or processes that are child processes of that shell.
t0rrant@testing:~$ bash -c echo $MYVAR
t0rrant@testing:~$In order to make variables available to child processes we need to use the export command.
t0rrant@testing:~$ export MYVAR="myvalue"
t0rrant@testing:~$ bash -c echo $MYVAR
myvalue
t0rrant@testing:~$Besides defining and displaying variables, we can interact with variables in interesting ways.
We can concatenate strings:
t0rrant@testing:~$ HELLO="Olá"
t0rrant@testing:~$ WORLD="Mundo!"
t0rrant@testing:~$ HELLOWORLD="$HELLO $WORLD"
t0rrant@testing:~$ echo $HELLOWORLD
Olá Mundo!
t0rrant@testing:~$We can do arithmetic operations with Integers by surrounding our operation with $(( ... )):
t0rrant@testing:~$ ONE=1
t0rrant@testing:~$ RESULT=$(($ONE+$ONE))
t0rrant@testing:~$ echo $RESULT
2
t0rrant@testing:~$We can mix it all up:
t0rrant@testing:~$ ONE=1
t0rrant@testing:~$ RESULT=$(($ONE+$ONE))
t0rrant@testing:~$ QUESTION="One plus One"
t0rrant@testing:~$ echo $QUESTION is $RESULT
One plus One is 2
t0rrant@testing:~$Shell arithmetic is complex and is not the focus of this section, if you would like to know more see the official documentation on the subject.
Special Variables
The shell treats several parameters specially. These parameters may only be referenced, assignment to them is not allowed. [9]
| Variable | Value Expansion |
|---|---|
| $* | Expands to the positional parameters, starting from one. When the expansion occurs within double quotes, it expands to a single word with the value of each parameter separated by the first character of the IFS special variable. |
| $@ | Expands to the positional parameters, starting from one. When the expansion occurs within double quotes, each parameter expands to a separate word. |
| $# | Expands to the number of positional parameters in decimal. |
| $? | Expands to the exit status of the most recently executed foreground pipeline. |
| $- | A hyphen expands to the current option flags as specified upon invocation, by the set built-in command, or those set by the shell itself (such as the -i). |
| $$ | Expands to the process ID of the shell. |
| $! | Expands to the process ID of the most recently executed background (asynchronous) command. |
| $0 | Expands to the name of the shell or shell script. |
| $_ | The underscore variable is set at shell startup and contains the absolute file name of the shell or script being executed as passed in the argument list. Subsequently, it expands to the last argument to the previous command, after expansion. It is also set to the full pathname of each command executed and placed in the environment exported to that command. When checking mail, this parameter holds the name of the mail file. |
Some of these variables are pretty useless for our previous interactions with the shell, however they are very useful for shell scripting, which we will take a look into in next section.
File Editing
One thing we have not covered yet is how to edit files. In Linux you have a lot of different options, be it a Graphical User Interface (GUI) or Command Line Interface (CLI) applications. If you talk to one user you will ear Vim, of course , it's very powerful, others will say Use Emacs, it's the best and most powerful!, well ... I say Use whatever tool you have the time to learn, and trust me when I say those two take some time to learn. I rather start off with something more simple and straight forward. However, if you would really like to know about those two and other CLI text editors you should check openvim and gnu pages.
In Ubuntu 20.04 you should have the following applications available:
- nano (CLI)
- gedit (GUI)
The most familiar for you to use is probably gedit as it is a windowed application where you can use your mouse to move around and scroll the file.
In this course I will focus on using the CLI, so we will be using nano in our examples.
nano is very simple, you execute the command with the name (or path) of the file you want to edit. If it exists, it is opened and you can edit it. If it does not, it is created.
Every command in nano is a combination of the CTRL key (indicated by ^ in the instructions) or the ALT key (indicated by M- in the instructions) followed by the shortcut key.
For example, let us create a file called test, write something in it, save it and exit.
t0rrant@testing:~$ nano test GNU nano 4.8 test
|
^G Get Help ^O Write Out ^W Where Is ^K Cut Text ^J Justify ^C Cur Pos M-U Undo
^X Exit ^R Read File ^\ Replace ^U Paste Text ^T To Spell ^_ Go To Line M-E RedoOn the first screen line we have the application name and our file name. On the second line is where our file contents start, where we see a blinking cursor is just like the one in the terminal.
On the bottom we have some helpful commands. After we wrote something in our file we would save by pressing the CTRL+O combination:
GNU nano 4.8 test Modified
Hello World!
File Name to Write: test|
^G Get Help M-D DOS Format M-A Append M-B Backup File
^C Cancel M-M Mac Format M-P Prepend ^T To FilesThe cursor is now on the bottom, so we could save the file with another name if we wanted, so we press Enter to confirm, to which the application replies how many lines it wrote:
GNU nano 4.8 test
Hello World!
[ Wrote 1 line ]
^G Get Help ^O Write Out ^W Where Is ^K Cut Text ^J Justify ^C Cur Pos M-U Undo
^X Exit ^R Read File ^\ Replace ^U Paste Text ^T To Spell ^_ Go To Line M-E RedoNow we exit by pressing CTRL+X.
If we had not saved the file before exiting, nano would ask us if we wanted to save the file, and we would type Y or N and press Enter, which would be followed by a prompt to choose the filename if we typed Y.
Scripting in Bash
Like we saw in File Types, in Linux the beginning of a file is what tells us the type of the file and even what application the file is supposed to be executed with. For Bash scripts we always start the file with a shebang (#!) followed by the path to the env command and bash as its argument
#!/usr/bin/env bashImagine we want to create a file named test.sh which should display our username, relative path to itself, and the name of the machine it is running on, its content could be:
| |
After saving the file and closing nano we need to make that file executable (remember File Attributes and Ownership):
t0rrant@testing:~$ chmod 755 test.shAnd execute it, by indicating a path to the file:
t0rrant@testing:~$ ./test.sh
I am t0rrant, and I just ran ./test.sh at testingNetworking 101
Nowadays we have an assortment of devices connected to the Internet and most of us have something similar to Figure 5 in our homes, a wireless router provided by our Internet Service Provider (ISP) which connects our wired and wireless devices to the Internet.

Common household network infrastructure
Inside our home wireless router there is actually a combination of several components:
- a network switch
- a network modem
- a network router
- a DNS server (nameserver)
we will see the function for each of these components as we move along each subsection.
There are four key concepts I would like to present in this section:
- Network Communications
- Switching
- Routing
- Domain Name System (DNS)
Network Communication
Network devices communicate with each other in a way that resembles a very awkward and very formal conversation.
Comparing a network communication to a human conversation between Alice and Bob, it could go something like this:
As you can see for every statement Alice makes, Bob acknowledges that statement, and there are two distinct protocols for initiating and terminating a conversation.
With network devices we need:
- a way to identify a device
- a way to reach a specific device
- a way to represent a message
- a way to represent which service in the device we want to deliver the message to
The first is called a Media Access Control (MAC) address, and is a unique identifier assigned to every Network Interface Controller (NIC).
The second is called an Internet Protocol (IP) address, and is a numerical assignment for a specific device. For simplicity we will only consider IPv4 addresses which are made up of four numbers, ranging from 0 to 254 and are separated by a dot (.) (i.e: 192.168.0.254).
The third is called a packet, and is what devices send to each other through the network. Each message exchanged between devices can be very small or very large, so these messages may need to be broken down into smaller packets, this is done by each network device.
The fourth is called a network port, and it usually identifies a process or network service waiting for messages (listening). This is a software port, a physical port is where physical cables connect to.
Imagine the IP address as being an address for a certain store in a mall, but it just identifies the building, the port identifies the number of the actual store, the actual endpoint where you can find your wanted service. You would not be going to an electronics store asking for beer right? =P
So, every network packet, should have a source IP address with its port and a destination IP address with its port in order to know where to exactly send the message to and where we expect to be replied to. This is very similar to traditional mail, just more complicated than sending a letter.
The MAC address association with an IP address also exists, but it is treated only within the local network and that is a whole other subject(s).
Switching
To filter and deliver these packets to its correct destination we have the network switch, which connects several network devices and "knows" where to which port to send each packet that arrives at another port.
In Figure 6, we can see an example of a switch with four connected devices. Each device will have a network interface connected to one of the switch's network ports (or the wireless interface) and the switch will know which IP address is associated with which MAC address. In example, if a packet arrives to the switch that has the TV's IP address as destination, only the TV will receive that packet.

Network Switch forming a network of devices
So, having a switch with connected devices defines a network between those devices.
Routing
In our home router we have a modem that connects to our ISP and gives us access to the Internet, but that modem will not do much more by itself, it is just a way to make a path to the ISP.
To have our packets being forwarded to the Internet we need the router.
The main functions of a router are:
- connecting multiple networks
- forwarding network packets
In Figure 7 we can see an example of two networks connected through the Internet. Every network that connects to the Internet will usually follow this setup.

Two networks connected by routers through the Internet
Our local router makes it possible to connect from our to a different network connected to another router, or a different network connected to the same router.
Sending a packet from our device with a local IP address to another device in a different network is made possible due to a process called Network Address Translation (NAT). I will not delve into it here, but broadly speaking it is a way for your router to hide your device information, exposing only itself in any forwarded packet, while at the same time maintaining a record of the origin for each forwarded packet in order to deliver any response to their proper recipient.
DNS
The Domain Name System (DNS) works somewhat like an old phone list. It is a dynamic set of servers that have records corresponding, among other record types, names to IPv4 addresses (Alias or A records). For example, the name implement.pt matches the A record corresponding to the IPv4 addresses:
- 104.24.106.10
- 104.24.107.10
- 172.67.136.196
which corresponds to three different entry points to access this name.
This record keeping is recursive, meaning that when you contact a certain DNS server it will search its own records for a match, and if it fails to find a match it will ask that information to another DNS server. This goes on until either a record is found, returning it back to the user, or no more DNS servers are available to ask to, in which case something like a "I do not know that record" is returned.
Taking a look at Figure 8 we can see an example of what happened when the device you are using to access this article tried to reach implement.pt.

DNS request flow example
First your device searched its internal records, and probably did not find anything.
Then it asked the next DNS Server, which is usually your router.
Your home router should also not have any records for implement.pt, and if so it asked its default DNS Servers for it. Usually these are your ISP's DNS servers. If they also do not have any record they will ask another, and another, until eventually some DNS server replied with the answer "implement.pt. A 104.24.107.10" and voilá your router can now pass that response to your device, which it did or else you would not be reading this =).
After your device has this information it can finally connect to the server at the correct address and initiate communication with this server at a specified port, in this case port 443.
Secure Communications and SSH
Encryption is the process of converting messages, information, or data into a form unreadable by anyone except the intended recipient. Encrypted data must be deciphered, or decrypted, before it can be read by the recipient. The root of the word encryption—crypt—comes from the Greek word kryptos, meaning hidden or secret. [15]
The first known form of encryption was used around 1900 BC! by an egyptian scribe using non-standard hieroglyphs, and it kept evolving from inscriptions in stone using signatures to authenticate its origin, to reversed-alphabet substitutions and other shifted substitutions. [15]
A very famous one is the Caesar Cipher, named after the roman emperor Julius Caesar, which used a simple substitution with the normal alphabet. For example, we could shift the alphabet left three places:
Plain: ABCDEFGHIJKLMNOPQRSTUVWXYZ
Cipher: XYZABCDEFGHIJKLMNOPQRSTUVWand if we wanted to send the message "ATTACK AT DAWN":
Plaintext: ATTACK AT DAWN
Ciphertext: XQQXZH XQ AXTKwe would send the message "XQQXZH XQ AXTK" and only who knew the cipher we were using would be able to know the correct message.
Symmetric vs Asymmetric Cryptography
Today’s crypto systems are divided into two categories: [15]
- symmetric
- asymmetric
Symmetric cryptography uses the a unique key (the secret key) to encrypt and decrypt a message. We can view this as a simple lock which only opens with a correct key, like we can see in Figure 9

Symmetric cryptography analogy
Asymmetric (or public key) cryptography uses one key (public key) to encrypt the message and a different key (private key) to decrypt the message. [15] One of the advantages is that there can be unending copies of the public key without compromising the private key.
By far the best non-technical explanation I have seen was shared by Panayotis Vryonis in his blog and I will share it here with you.
Picture a box with a lock, but this lock is special (see Figure 10). It fits two separate keys (yes, two). The first one can only turn clockwise (from A to B to C), let us call this the private key, and the second one can only turn counter-clockwise (from C to B to A), let us call this the public key. [10]

Asymmetric cryptography analogy
With this we can do two things to an unlocked box:
- lock with the private key
- lock with the public key
If we lock with the public key, only the person with the private key will be able to open it, and so anyone with the public key will be able to send secret items safely inside the box, knowing that only the owner of the private key will be able to access them.
If we lock the box with the private key, anyone that has the public key and can open the box can be sure that the box was locked by whoever possesses the private key counterpart, which makes them sure that whatever is inside the box it was placed by the one person holding the private key.
For example, Bob has one of these specials boxes, keeps one copy of the secret key for himself, and makes lots of copies of the public key. He then spreads those copies around, his house, office, random mailboxes, subway, and gives copies to all of his friends, including his close friend Alice.
Alice wants to send a secret message to Bob. She has a box with this special lock made by Bob. She can put a message inside the box and turn the lock to the locked position A. Then she can pass the box to anyone (that will eventually deliver the box to Bob, of course) sure that only Bob will be able to use his secret key to move the lock to the unlocked position B.
Now imagine that Alice receives a box from someone, saying it has a message from Bob. But how can Alice be sure it was Bob that sent it? Easily enough, if the public key that Bob gave her can open the box then the box surely came from Bob.
Secure Shell (SSH)
The SSH protocol (also referred to as Secure Shell) is a method for secure remote login from one computer to another. It provides several alternative options for strong authentication, and it protects the communications security and integrity with strong encryption. [12]
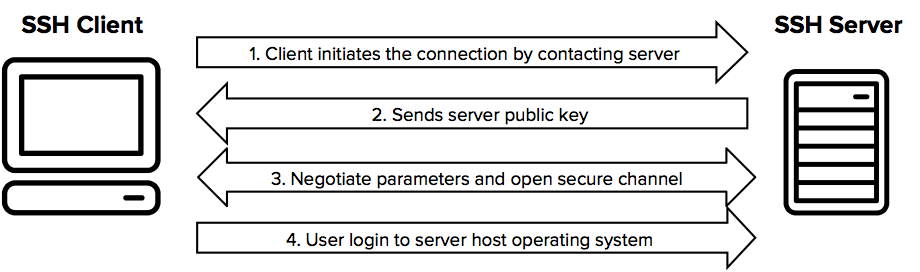
SSH protocol [12]
When using SSH, we are using the same concepts we saw earlier about asymmetric cryptography. As we can see in Figure 11, the SSH Client first contacts the SSH Server through an insecure communication channel (the network), so after the SSH Server sends the Client its public key, they use a really crafty way of having a common secret without anyone in that insecure channel being able to know what it is. [14]
In Figure 12 we can see an analogy of this ingenious process, of sharing secrets through an insecure channel, with colors instead of very large numbers (which is what roughly happens in a real-world interaction), this process is called the Diffie-Hellman Key Exchange.

Sharing a common secret through a non-secure channel [13]
The process begins by having the two actors, Alice and Bob, agree on one color that does not need to be kept secret. In this example, the color is yellow.
Each of them also has a secret color that they keep to themselves, in this case red for Alice, teal for Bob.
The crafty part of the process is that Alice and Bob each mix their own secret color together with their initially shared color (yellow), resulting in an orange-tan color for Alice and a light-blue mix for Bob.
They can now exchange the resulting mixed colors publicly, we assume that separating the mixed colors back to their original individual colors takes too long and is very expensive.
Finally, they each mix the color they received from the previous exchange with their own secret color.
The final result is a color mixture (yellow-brown in this case) that is identical for both.
If someone saw the exchange, they would only know the common color (yellow) and the first mixed colors (orange-tan and light-blue), but it would be extremely difficult for them to know the resulting secret color (yellow-brown).
Bringing the analogy back to a real-life exchange using large numbers instead of colors, this determination is computationally expensive. It is impossible to compute in a practical amount of time. [13]
Finally, after this "simple" key exchange the SSH Client and Server are ready to communicate securely.
Setting up your machine for remote access
Now that we have covered BASH interaction, file manipulation, networking and secure communications, we are ready to setup network communications between our two machines and perform interactions between them, in a secure manner.
For this section we will assume our workstation to be called testing and that it has the IPv4 address 192.168.1.10, and our other machine will be called remote-server and it has the IPv4 address 192.168.1.11.
We also assume that a user with the same name exists on both of those machines, in this case the user is t0rrant.
| Hostname | IPv4 Address |
|---|---|
| testing | 192.168.1.10 |
| remote-server | 192.168.1.11 |
To find out your real IPv4 addresses you can use the ip command, as such:
t0rrant@remote-server:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp3s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN group default qlen 1000
link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff
3: enp3s1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff
inet 192.168.1.11/24 brd 192.168.1.255 scope global dynamic noprefixroute enp3s1
valid_lft 67476sec preferred_lft 67476secFrom the output above you should notice three things, as you should see something similar in your machine, the interface names are probably different and can be something like eth0, wlan1 or wlo1.
The interface name, which is after each number in the list:
1: lo
...
2: enp3s0
...
3: enp3s1
...The interface status:
1: lo: ... state UNKNOWN ...
...
2: enp3s0: ... state DOWN ...
...
3: enp3s1 ... state UP ...
...Interfaces with their state UP should be the ones that are connected, and thus have an IP address (inet):
1: lo: ... state UNKNOWN ...
...
2: enp3s0: ... state DOWN ...
...
3: enp3s1 ... state UP ...
...
inet 192.168.1.11/24 ...The /24 portion, broadly speaking, defines the size of the network your machine is connected to. What you need is the first part, so in this case we can see that the IPv4 address for the enp3s1 interface in the remote-server is 192.168.1.11.
Server Application Setup
First let us install the server application:
t0rrant@remote-server:~$ sudo apt install openssh-client openssh-serverAnd now we can start the service
t0rrant@remote-server:~$ sudo systemctl start sshsee that it is running
t0rrant@remote-server:~$ sudo systemctl status ssh
● ssh.service - OpenBSD Secure Shell server
Loaded: loaded (/lib/systemd/system/ssh.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-05-11 15:24:03 WEST; 5s ago
Docs: man:sshd(8)
man:sshd_config(5)
Process: 9523 ExecStartPre=/usr/sbin/sshd -t (code=exited, status=0/SUCCESS)
Main PID: 9524 (sshd)
Tasks: 1 (limit: 38302)
Memory: 1.4M
CGroup: /system.slice/ssh.service
└─9524 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
mai 11 15:24:03 testing systemd[1]: Starting OpenBSD Secure Shell server...
mai 11 15:24:03 testing sshd[9524]: Server listening on 0.0.0.0 port 22.
mai 11 15:24:03 testing sshd[9524]: Server listening on :: port 22.
mai 11 15:24:03 testing systemd[1]: Started OpenBSD Secure Shell server.and from our workstation test the connection:
t0rrant@testing:~$ ssh t0rrant@192.168.1.11
t0rrant@odin's password:
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-29-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Mon May 11 15:25:44 WEST 2020
System load: 0.6
Usage of /: 22.3% of 9.32GB
Memory usage: 35%
Swap usage: 0%
Processes: 102
Users logged in: 0
IPv4 address for enp3s1: 192.168.1.11
0 updates can be installed immediately.
0 of these updates are security updates.
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
t0rrant@remote-server:~$SSH Keypair Setup
Entering our password every time we connect to a remote server is more than tedious, it opens the possibility for someone else to be able to "guess" our password. Of course we can find ways to remedy this, we can generate a random password with 20+ characters, we can setup defense mechanisms to "lock out" anyone that fails to enter the correct password some number of times, some other convoluted solution or we could gather the knowledge we gained from secure communications and SSH and make use of asymmetric cryptography not only to perform secure communications, but also to authenticate ourselves with the server.
Remember that section, and remember that if our "box" was locked with our public key, it can only be unlocked with our private key, so if the server would send a message encrypted with our public key we could only send back the same message if we have the correct private key. Essentially what we are doing is receiving one "box" locked with our public key, unlocking it with our private key, and finally we send a new "box" to the server locked with the server's public key, which we have because the server sent it to us on our first connect (as seen in Figure 11).
In Figure 13 we can see a sequence of this process.
{kind=link}
So, let us get on to generating the keys for our special lock =)
When we installed openssh-client it also came with a couple of useful tools, one of them is ssh-keygen, which conveniently lets us generate a pair of keys:
t0rrant@testing:~$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/t0rrant/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/t0rrant/.ssh/id_rsa
Your public key has been saved in /home/t0rrant/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:ILvTwLzlzZyMS7YFflmMY+WxCG7BjkN4VCRg5tae3WI t0rrant@testing
The key's randomart image is:
+---[RSA 3072]----+
| +.ooo |
| + + o |
| + = = o |
| . * O = * o |
| X E S = |
| % X = |
| + B X |
| + = |
| o |
+----[SHA256]-----+One other tool is ssh-copy-id, which adds our public key to a server, for a specific user (the one we connect with):
t0rrant@testing:~$ ssh-copy-id t0rrant@192.168.1.11
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: ".ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 't0rrant@192.168.1.11'"
and check to make sure that only the key(s) you wanted were added.
t0rrant@testing:~$Let us try a new connection from our testing workstation to our remote-server:
t0rrant@testing:~$ ssh t0rrant@192.168.1.11
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-29-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Mon May 11 15:34:40 WEST 2020
System load: 0.6
Usage of /: 22.3% of 9.32GB
Memory usage: 35%
Swap usage: 0%
Processes: 102
Users logged in: 0
IPv4 address for enp3s1: 192.168.1.11
0 updates can be installed immediately.
0 of these updates are security updates.
Last login: Mon May 11 15:25:44 2020 from 192.168.1.10
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
t0rrant@remote-server:~$Notice that this time it did not ask us for our user's password, success :)
Now that we have access through our keypair, we can configure the server to not accept password based logins, only accept keypair based ones.
Open (as root) the /etc/ssh/sshd_config file for editing
t0rrant@remote-server:~$ sudo nano /etc/ssh/sshd_configsearch for the options PubkeyAuthentication and PasswordAuthentication and change them to yes and no, respectively, as so:
PubkeyAuthentication yes
PasswordAuthentication nomake sure none of those lines start with a #, if they do remove it.
Save and exit by pressing CTRL+O and then CTRL+X.
Finally, restart the application
t0rrant@remote-server:~$ sudo systemctl restart sshdo not lose or share your private key, and do not forget the passphrase!
Network Interactions
Now that we have a functional client-server connection, what can we really do with it?
First of all, we are getting pretty tired of typing the remote-server IPv4 address, it would be way better if we could simply do
ssh remote-serverand we can! Recalling the network name resolution in the previous section on DNS, when we search for the IPv4 address of a specific hostname, the Linux operating system does not go straight to the DNS servers asking for it. It actually has an internal name resolver which, among other things, reads information from a special file located at /etc/hosts. There we can define our own records, that can be (almost) whatever we want.
If you check its contents (for the sake of simplicity we will ignore IPv6 settings):
t0rrant@testing:~$ cat /etc/hosts
127.0.0.1 localhost
t0rrant@testing:~$you can see that the name localhost is an alias for the 127.0.0.1 IPv4 address, which is that special address we discussed earlier in Networking 101 that represents our own machine.
As easily as that, we can add an entry for our remote-server, using nano, which leaves the file as such:
t0rrant@testing:~$ cat /etc/hosts
127.0.0.1 localhost
192.168.1.11 remote-server
t0rrant@testing:~$Note that the hyphen (-) is the only non-alphanumeric character allowed in a hostname (for more information see the man pages for hostname)
And now we can connect to remote-server without typing its IPv4 address:
t0rrant@testing:~$ ssh t0rrant@remote-server
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-29-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Mon May 11 15:56:12 WEST 2020
System load: 0.6
Usage of /: 22.3% of 9.32GB
Memory usage: 35%
Swap usage: 0%
Processes: 102
Users logged in: 0
IPv4 address for enp3s1: 192.168.1.11
0 updates can be installed immediately.
0 of these updates are security updates.
Last login: Mon May 11 15:34:40 2020 from 192.168.1.10
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
t0rrant@remote-server:~$Besides connecting to our remote server and interacting with it from within a shell, we can also do other types of operations through SSH.
We can send a file:
t0rrant@testing:~$ scp test.sh remote-server:~/test.sh
test.sh 100% 278 1.2MB/s 00:00
t0rrant@testing:~$We can retrieve a file:
t0rrant@testing:~$ scp remote-server:~/test.sh test2.sh
test.sh 100% 278 1.2MB/s 00:00
t0rrant@testing:~$We can run commands remotely:
t0rrant@testing:~$ ssh remote-server ~/test.sh
I am t0rrant, and I just ran /home/t0rrant/test.sh at remote-server
t0rrant@testing:~$Conclusion
There is no place like 127.0.0.1
In this course we touched several aspects of the Linux ecosystem. Its origins, what components make the Linux Kernel, learned how to use some of its tools, and culminated in communicating between two machines through a network.
These were a lot of concepts to take in at once, so I hope you took your breaks and took your time exploring some of the concepts on your own.
I invite you to explore further, remember that a using a search engine is a good way of finding information but sometimes the Man Pages are even friendlier.
Hopefully this was useful and you could follow and replicate the examples =)
Feel free to leave comments below, any improvement to this and other articles is always welcome.
Thanks for reading!
References
| [1] | --, Secure Programming for Linux and Unix HOWTO - The Linux Documentation Project [link] |
| [2] | Richard Stallman, Linux and GNU - The GNU Project - FSF Foundation [link] |
| [3] | Linus Torvalds, The Linux edge - Communications of the ACM, Volume 42, Number 4 (1999), Pages 38-39 [link] |
| [4] | --, History of Linux - Wikipedia [link] |
| [5] | --, Linux - Linux Foundation [link] |
| [6] | --, Bash Reference Manual - GNU Software [link] |
| [7] | (1, 2, 3) --, Linux Filesystem Hierarchy - The Linux Documentation Project [link] |
| [8] | --, User Authentication HOWTO - The Linux Documentation Project [link] |
| [9] | (1, 2) --, Bash Guide for Beginners - The Linux Documentation Project [link] |
| [10] | Panayotis Vryonis, public-key cryptography for non-geeks [link] |
| [11] | --, Introduction to Linux, Chapter 3, The Linux Documentation Project [link] |
| [12] | (1, 2) Tatu Ylonen, SSH - Secure Login Connections over the Internet. Proceedings of the 6th USENIX Security Symposium, pp. 37-42, USENIX, 1996. |
| [13] | (1, 2) --, Diffie-Hellman key exchange - Wikipedia [link] |
| [14] | Whitfield Diffie and Martin E. Hellman, New Directions in Cryptography. IEEE Transactions on Information Theory, vol. IT-22, no. 6, November 1976. [link] |
| [15] | (1, 2, 3, 4) Melis Jacob, History of Encryption. Information Security Reading Room, SANS Institute, 2020. |
Tags: gnu linux filesystem networking fundamentals bash
Related Content
- Hacking diskimage-builder for Fun and Profit
- Virtualenvwrapper Installation and Usage
- Creating Custom Resources for Your Cookbooks
- Hitchhiker's Guide to Chef
- An Advanced Guide to Salt